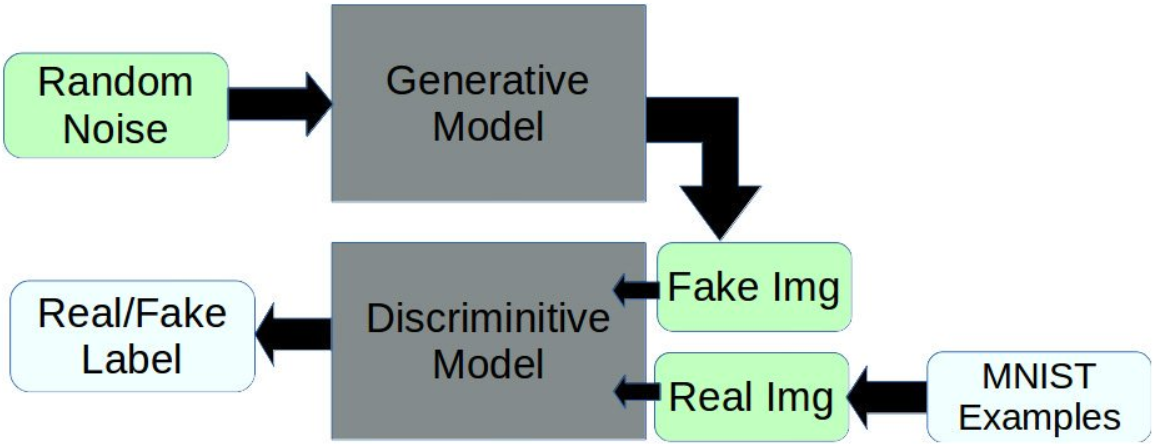
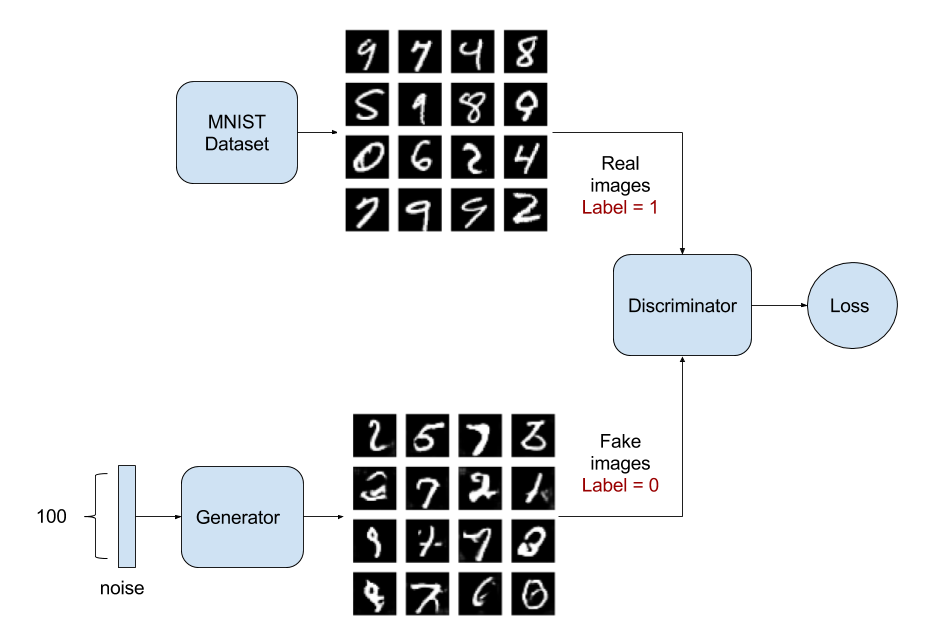
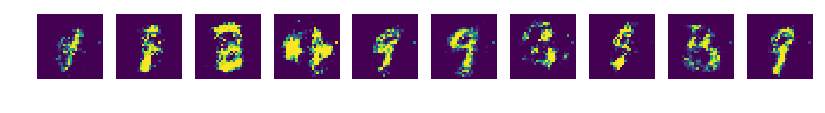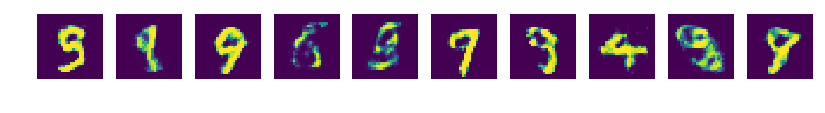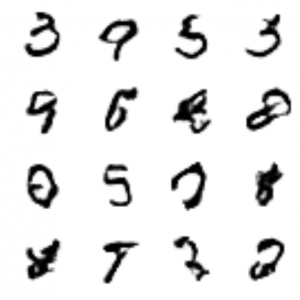GAN(Generative Adversarial Nets) 모델은 대립하는 두개의 신경망을 서로 경쟁시켜 결과물을 생성하는 방법을 학습하게 하는 모델입니다.
“Adversarial”이란 단어의 사전적 의미를 보면 대립하는, 적대하는 란 뜻을 갖습니다. 대립하려면 어찌 되었든 상대가 있어야하니 GAN은 크게 두 부분으로 나누어져 있다는 것을 먼저 직관적으로 알 수 있습니다.
By Tim O’Shea, O’Shea Research.
Some of the generative work done in the past year or two using generative adversarial networks (GANs) has been pretty exciting and demonstrated some very impressive results. The general idea is that you train two models, one (G) to generate some sort of output example given random noise as input, and one (A) to discern generated model examples from real examples. Then, by training A to be an effective discriminator, we can stack G and A to form our GAN, freeze the weights in the adversarial part of the network, and train the generative network weights to push random noisy inputs towards the “real” example class output of the adversarial half.
GAN 모델을 제안한 이안 굿펠로우(Ian Goodfellow)가 논문에 제시한 비유에 의하면, 위조지폐범(생성자 신경망)과 경찰관(구분자 신경망)을 상호 대립시켜, 경찰은 감별하려고 노력하고, 위조지폐범은 위조방법을 고도화 하는 관계를 통해서 진짜와 구분하기 어려운 고도의 위조지폐를 만들수 있도록 학습 하게 하는 것 입니다.
importosimportsysimporttensorflowastfimportmatplotlib.pyplotaspltimportnumpyasnp# '루트'와 '작업'디렉토리 설정 - for 스크립트런
DIRS=os.path.dirname(__file__).partition("deep_MLDL")ROOT=DIRS[0]+DIRS[1]sys.path.append(ROOT)fromos.pathimportdirname,joinWORK_DIR=join(ROOT,'_static','MNIST_data','')fromtensorflow.examples.tutorials.mnistimportinput_datamnist=input_data.read_data_sets(WORK_DIR,one_hot=True)# Hyper- Parameter
learning_rate=2e-4training_epoches=100batch_size=100n_hidden=256n_input=28*28# 784 pix. for 1 letter
n_noise=128# placeholder
X=tf.placeholder(tf.float32,[None,n_input])Z=tf.placeholder(tf.float32,[None,n_noise])G_W1=tf.Variable(tf.random_normal([n_noise,n_hidden],stddev=0.01))G_b1=tf.Variable(tf.zeros([n_hidden]))G_W2=tf.Variable(tf.random_normal([n_hidden,n_input],stddev=0.01))G_b2=tf.Variable(tf.zeros([n_input]))D_W1=tf.Variable(tf.random_normal([n_input,n_hidden],stddev=0.01))D_b1=tf.Variable(tf.zeros([n_hidden]))D_W2=tf.Variable(tf.random_normal([n_hidden,1],stddev=0.01))D_b2=tf.Variable(tf.zeros([1]))